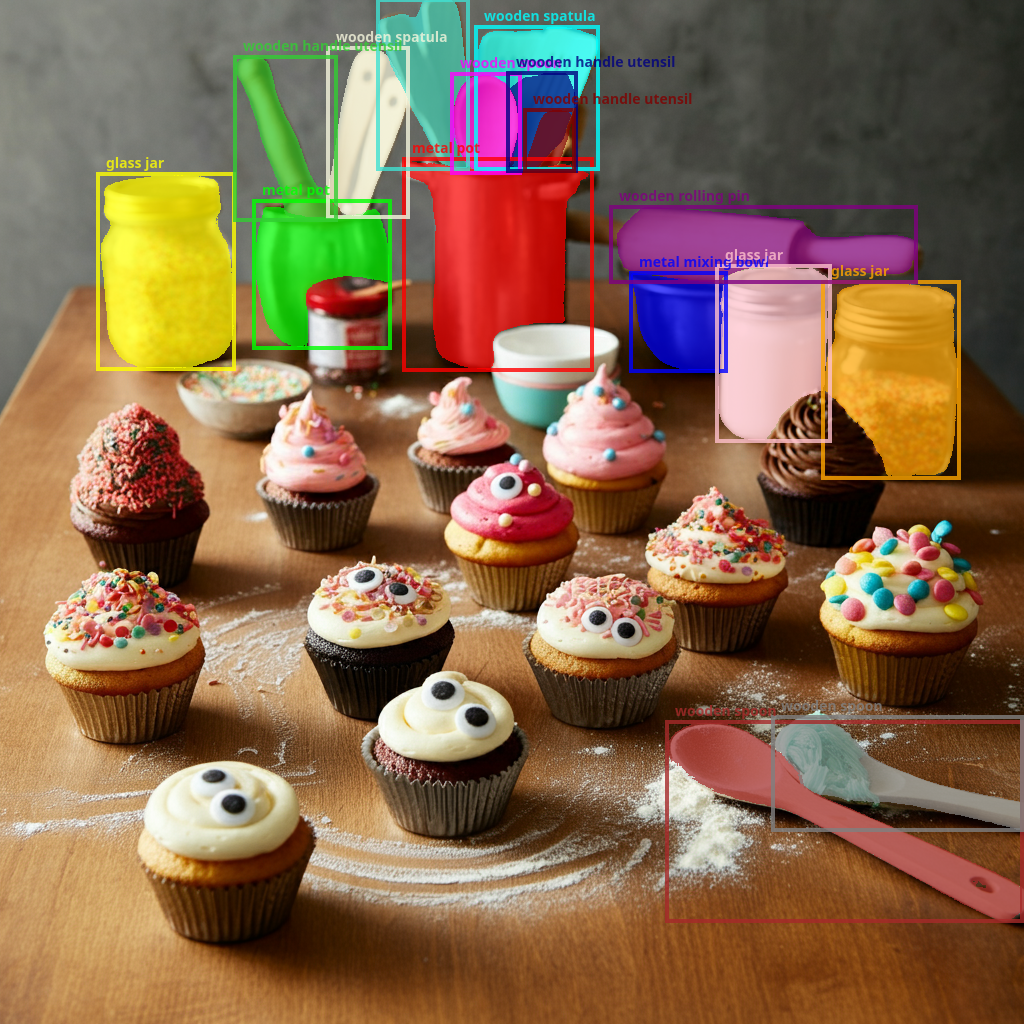This notebook introduces object detection and spatial understanding with the Gemini API like in the Spatial understanding example from AI Studio and demonstrated in the Building with Gemini 2.0: Spatial understanding video.
You’ll learn how to use Gemini the same way as in the demo and perform object detection like this:
BBOX Cupcakes
There are many examples, including object detection with
simply overlaying information
searching within an image
translating and understanding things in multiple languages
using Gemini thinking abilities
Note
There’s no “magical prompt”. Feel free to experiment with different ones. You can use the dropdown to see different samples, but you can also write your own prompts. Also, you can try uploading your own images.
You can create your API key using Google AI Studio with a single click.
Remember to treat your API key like a password. Don’t accidentally save it in a notebook or source file you later commit to GitHub. In this notebook we will be storing the API key in a .env file. You can also set it as an environment variable or use a secret manager.
Another option is to set the API key as an environment variable. You can do this in your terminal with the following command:
$ export GEMINI_API_KEY="<YOUR_API_KEY>"
Load the API key
To load the API key from the .env file, we will use the dotenv package. This package loads environment variables from a .env file into process.env.
$ npm install dotenv
Then, we can load the API key in our code:
const dotenv =require("dotenv") astypeofimport("dotenv");dotenv.config({ path:"../.env",});const GEMINI_API_KEY =process.env.GEMINI_API_KEY??"";if (!GEMINI_API_KEY) {thrownewError("GEMINI_API_KEY is not set in the environment variables");}console.log("GEMINI_API_KEY is set in the environment variables");
GEMINI_API_KEY is set in the environment variables
Note
In our particular case the .env is is one directory up from the notebook, hence we need to use ../ to go up one directory. If the .env file is in the same directory as the notebook, you can omit it altogether.
With the new SDK, now you only need to initialize a client with you API key (or OAuth if using Vertex AI). The model is now set in each call.
const google =require("@google/genai") astypeofimport("@google/genai");const ai =new google.GoogleGenAI({ apiKey: GEMINI_API_KEY });
Select a model
Spatial understanding works best Gemini 2.0 Flash model. It’s even better with 2.5 models like gemini-2.5-pro-preview-05-20 but slightly slower as it’s a thinking model.
Some features, like segmentation, only works with 2.5 models.
You can try with the older ones but it might be more inconsistent (gemini-1.5-flash-001 had the best results of the previous generation).
For more information about all Gemini models, check the documentation for extended information on each of them.
With the new SDK, the systemInstruction and the model parameters must be passed in all generateContent calls, so let’s save them to not have to type them all the time.
const BOUNDING_BOX_SYSTEM_INSTRUCTION =` Return bounding boxes as a JSON array with labels. Never return masks or code fencing. Limit to 25 objects. If an object is present multiple times, name them according to their unique characteristic (colors, size, position, unique characteristics, etc..).`;
The system instructions are mainly used to make the prompts shorter by not having to reapeat each time the format. They are also telling the model how to deal with similar objects which is a nice way to let it be creative.
The Spatial understanding example is using a different strategy with no system instructions but a longer prompt. You can see their full prompts by clicking on the “show raw prompt” button on the right. There no optimal solution, experiment with diffrent strategies and find the one that suits your use-case the best.
Utilities
Some scripts will be needed to draw the bounding boxes. Of course they are just examples and you are free to just write your own.
Socks.jpg already exists at ../assets/spatial_understanding/Socks.jpg
Vegetables.jpg already exists at ../assets/spatial_understanding/Vegetables.jpg
Japanese_bento.png already exists at ../assets/spatial_understanding/Japanese_bento.png
Cupcakes.jpg already exists at ../assets/spatial_understanding/Cupcakes.jpg
Origamis.jpg already exists at ../assets/spatial_understanding/Origamis.jpg
Fruits.jpg already exists at ../assets/spatial_understanding/Fruits.jpg
Cat.jpg already exists at ../assets/spatial_understanding/Cat.jpg
Pumpkins.jpg already exists at ../assets/spatial_understanding/Pumpkins.jpg
Breakfast.jpg already exists at ../assets/spatial_understanding/Breakfast.jpg
Bookshelf.jpg already exists at ../assets/spatial_understanding/Bookshelf.jpg
Spill.jpg already exists at ../assets/spatial_understanding/Spill.jpg
Overlaying Information
Let’s start by loading an image, the cupcakes one for example:
Let’s start with a simple prompt to find all items in the image.
To prevent the model from repeating itself, it is recommended to use a temperature over 0, in this case 0.5. Limiting the number of items (25 in the system instructions) is also a way to prevent the model from looping and to speed up the decoding of the bounding boxes. You can experiment with these parameters and find what works best for your use-case.
const boundingBoxesResponse =await ai.models.generateContent({ model: MODEL_ID, contents: ["Detect the 2d bounding boxes of the cupcakes (with “label” as topping description”)", google.createPartFromBase64(fs.readFileSync(CUPCAKE_IMAGE_PATH).toString("base64"),"image/jpeg"), ], config: { systemInstruction: BOUNDING_BOX_SYSTEM_INSTRUCTION, temperature:0.5, },});console.log(boundingBoxesResponse.text);
```json
[
{"box_2d": [389, 64, 570, 201], "label": "Dark chocolate cupcake with red and pink sprinkles"},
{"box_2d": [383, 250, 538, 367], "label": "Light pink frosting with small pink sprinkles"},
{"box_2d": [366, 397, 501, 506], "label": "Pink frosting with light blue candy balls"},
{"box_2d": [353, 529, 521, 650], "label": "Pink frosting with blue candy balls"},
{"box_2d": [384, 737, 535, 865], "label": "Plain chocolate frosting cupcake"},
{"box_2d": [476, 627, 636, 768], "label": "White frosting with red, yellow, blue, and pink sprinkles (top-right)"},
{"box_2d": [509, 799, 688, 959], "label": "White frosting with red, yellow, blue, and pink sprinkles (middle-right)"},
{"box_2d": [554, 40, 723, 199], "label": "White frosting with mixed colorful sprinkles (front-left)"},
{"box_2d": [546, 296, 700, 442], "label": "White frosting with candy eyes and yellow/red sprinkles (middle-left)"},
{"box_2d": [442, 433, 595, 563], "label": "Bright pink frosting with candy eyes"},
{"box_2d": [559, 514, 712, 663], "label": "White frosting with candy eyes and yellow/red sprinkles (middle-right)"},
{"box_2d": [743, 134, 919, 306], "label": "White frosting with two candy eyes (bottom-left)"},
{"box_2d": [655, 354, 815, 513], "label": "White frosting with two candy eyes (bottom-right)"}
]
```
As you can see, even without any instructions about the format, Gemini is trained to always use this format with a label and the coordinates of the bounding box in a “box_2d” array.
Just be careful, the y coordinates are first, x ones afterwards contrary to common usage.
Let’s complicate things and search within the image for specific objects.
const SOCKS_IMAGE_PATH = path.join("../assets/spatial_understanding/Socks.jpg");const socksBoundingBoxesResponse =await ai.models.generateContent({ model: MODEL_ID, contents: ["Show me the positions of the socks with the face", google.createPartFromBase64(fs.readFileSync(SOCKS_IMAGE_PATH).toString("base64"),"image/jpeg"), ], config: { systemInstruction: BOUNDING_BOX_SYSTEM_INSTRUCTION, temperature:0.5, },});console.log(socksBoundingBoxesResponse.text);
[
{"box_2d": [240, 650, 649, 860], "label": "socks with the face"},
{"box_2d": [53, 248, 384, 524], "label": "socks with the face"}
]
Try it with different images and prompts. Different samples are proposed but you can also write your own.
Multilinguality
As Gemini is able to understand multiple languages, you can combine spatial reasoning with multilingual capabilities.
You can give it an image like this and prompt it to label each item with Japanese characters and English translation. The model reads the text and recognize the pictures from the image itself and translates them.
const JAPANESE_BENTO_IMAGE_PATH = path.join("../assets/spatial_understanding/Japanese_bento.png");const japaneseBentoBoundingBoxesResponse =await ai.models.generateContent({ model: MODEL_ID, contents: ["Detect food, label them with Japanese characters + english translation.", google.createPartFromBase64(fs.readFileSync(JAPANESE_BENTO_IMAGE_PATH).toString("base64"),"image/png"), ], config: { systemInstruction: BOUNDING_BOX_SYSTEM_INSTRUCTION, temperature:0.5, },});console.log(japaneseBentoBoundingBoxesResponse.text);
The model can also reason based on the image, you can ask it about the positions of items, their utility, or, like in this example, to find the shadow of a speficic item.
const ORIGAMI_IMAGE_PATH = path.join("../assets/spatial_understanding/Origamis.jpg");const origamiBoundingBoxesResponse =await ai.models.generateContent({ model: MODEL_ID, contents: ["Draw a square around the fox' shadow", google.createPartFromBase64(fs.readFileSync(ORIGAMI_IMAGE_PATH).toString("base64"),"image/jpeg"), ], config: { systemInstruction: BOUNDING_BOX_SYSTEM_INSTRUCTION, temperature:0.5, },});console.log(origamiBoundingBoxesResponse.text);
You can also use Gemini knowledge to enhanced the labels returned. In this example Gemini will give you advices on how to fix your little mistake.
const SPILL_IMAGE_PATH = path.join("../assets/spatial_understanding/Spill.jpg");const spillBoundingBoxesResponse =await ai.models.generateContent({ model: MODEL_ID, contents: ["Tell me how to clean my table with an explanation as label. Do not just label the items", google.createPartFromBase64(fs.readFileSync(SPILL_IMAGE_PATH).toString("base64"),"image/jpeg"), ], config: { systemInstruction: BOUNDING_BOX_SYSTEM_INSTRUCTION, temperature:0.5, },});console.log(spillBoundingBoxesResponse.text);
```json
[
{"box_2d": [447, 0, 1000, 417], "label": "cleaning cloth: Use this cloth to gently blot and wipe the spilled liquid from the table surface."},
{"box_2d": [432, 606, 663, 874], "label": "liquid spill: This is the substance that needs to be cleaned from the table."},
{"box_2d": [200, 299, 508, 517], "label": "sugar bowl: Move this item aside to ensure thorough cleaning of the table surface underneath and around it."},
{"box_2d": [106, 556, 220, 699], "label": "sugar container: Move this item aside to ensure thorough cleaning of the table surface underneath and around it."},
{"box_2d": [287, 140, 467, 314], "label": "knives: Carefully move these sharp objects to a safe location before cleaning to prevent injury and allow full access to the table surface."},
{"box_2d": [108, 843, 360, 1000], "label": "wooden object: Move this item aside to ensure thorough cleaning of the table surface underneath and around it."},
{"box_2d": [113, 224, 280, 492], "label": "wooden stand: Move this item aside to ensure thorough cleaning of the table surface underneath and around it."},
{"box_2d": [121, 120, 361, 229], "label": "wooden dowel: This is part of the wooden stand; move it with the stand to clear the area for cleaning."}
]
```
And if you check the previous examples, the Japanese food one in particular, multiple other prompt samples are provided to experiment with Gemini reasoning capabilities.
Experimental: Segmentation
2.5 models are also able to segment the image and not only draw a bounding box but to also provide a mask of the contour of the items. It’s especially useful if you are planning on editing images like in the Virtual try-on example.
const SEGMENTATION_PROMPT ='Give the segmentation masks for the metal, wooden and glass small items (ignore the table). Output a JSON list of segmentation masks where each entry contains the 2D bounding box in the key "box_2d", the segmentation mask in key "mask", and the text label in the key "label". Use descriptive labels.';const segmentationResponse =await ai.models.generateContent({ model: MODEL_ID, contents: [ SEGMENTATION_PROMPT, google.createPartFromBase64(fs.readFileSync(CUPCAKE_IMAGE_PATH).toString("base64"),"image/jpeg"), ], config: { temperature:0.5, },});console.log(segmentationResponse.text);
The model predicts a JSON list, where each item represents a segmentation mask. Each item has a bounding box ("box_2d") in the format [y0, x0, y1, x1] with normalized coordinates between 0 and 1000, a label ("label") that identifies the object, and lastly the segmentation mask inside the bounding box, as base64 encoded png.
To use the mask, first you need to do base64 decoding, and then loading this string as a png. This will give you a probability map with values between 0 and 255. The mask needs to be resized to match the bounding box dimensions, then you can apply your confidence threshold, e.g. binarizing at 127 for the midpoint. Finally, pad the mask into an array of the size of the full image.
All these steps are done by the the parseSegmentationMasks function provided earlier.
Ultimately, use the plotSegmentationMasks function to visualize the decoded masks by overlaying it on the image.
Related to image recognition and reasoning, Market a jet backpack and Guess the shape examples are worth checking to continue your Gemini API discovery (Note: these examples still use the old SDK). And of course the pointing and 3d boxes example referenced earlier.