LLMs are powerful tools, but are not intrinsically connected to live data sources. Features like Google Search grounding provide fresh information using Google’s search index, but to supply truly live information, you can connect a browser to provide up-to-the-minute data and smart exploration.
This notebook will guide you through three examples of using a browser as a tool with the Gemini API, using both the Live Multimodal API and traditional turn-based conversations.
Requesting live data using a browser tool with the Live API
Returning images of web pages from function calling
Connecting to a local network/intranet using a browser tool
You can create your API key using Google AI Studio with a single click.
Remember to treat your API key like a password. Don’t accidentally save it in a notebook or source file you later commit to GitHub. In this notebook we will be storing the API key in a .env file. You can also set it as an environment variable or use a secret manager.
Another option is to set the API key as an environment variable. You can do this in your terminal with the following command:
$ export GEMINI_API_KEY="<YOUR_API_KEY>"
Load the API key
To load the API key from the .env file, we will use the dotenv package. This package loads environment variables from a .env file into process.env.
$ npm install dotenv
Then, we can load the API key in our code:
const dotenv =require("dotenv") astypeofimport("dotenv");dotenv.config({ path:"../.env",});const GEMINI_API_KEY =process.env.GEMINI_API_KEY??"";if (!GEMINI_API_KEY) {thrownewError("GEMINI_API_KEY is not set in the environment variables");}console.log("GEMINI_API_KEY is set in the environment variables");
GEMINI_API_KEY is set in the environment variables
Note
In our particular case the .env is is one directory up from the notebook, hence we need to use ../ to go up one directory. If the .env file is in the same directory as the notebook, you can omit it altogether.
│
├── .env
└── examples
└── Browser_as_tool.ipynb
Initialize SDK Client
With the new SDK, now you only need to initialize a client with you API key (or OAuth if using Vertex AI). The model is now set in each call.
const google =require("@google/genai") astypeofimport("@google/genai");const ai =new google.GoogleGenAI({ apiKey: GEMINI_API_KEY });
Select a model
Now select the model you want to use in this guide, either by selecting one in the list or writing it down. Keep in mind that some models, like the 2.5 ones are thinking models and thus take slightly more time to respond (cf. thinking notebook for more details and in particular learn how to switch the thiking off).
This example will show you how to use the Multimodal Live API with the Google Search tool, and then comparatively shows a custom web browsing tool to retrieve site contents in real-time.
Use Google Search as a tool
The streaming nature of the Live API requires that the stream processing and function handling code be written in advance. This allows the stream to continue without timing out.
This example uses text as the input mode, and streams text back out, but the technique applies any mode supported by the Live API, including audio.
// temporarily make console.warn a no-op to avoid warnings in the output (non-text part in GenerateContentResponse caused by accessing .text)// https://github.com/googleapis/js-genai/blob/d82aba244bdb804b063ef8a983b2916c00b901d2/src/types.ts#L2005// copy the original console.warn function to restore it laterconst warn_fn =console.warn;// eslint-disable-next-line @typescript-eslint/no-empty-function, no-empty-functionconsole.warn=function () {};awaitrun("What is today's featured article on the English Wikipedia?", google.Modality.TEXT, [{ googleSearch: {} }]);// restore console.warn later// console.warn = warn_fn;
Connection opened
print(google_search.search(queries=["what is today's featured article on english wikipedia"]))
Looking up information on Google Search.
Today’s featured article on the English Wikipedia is “Tritter”.
Depending on when you run this, you may note a discrepency between what Google Search has in its index, and what is currently live on Wikipedia. Check out Wikipedia’s featured article yourself. Alternatively, the model may decide not to answer due to the requirement for freshness.
To improve this situation, add a browse tool so the model can acquire this information in real-time.
Add a live browser
This step defines a “browser” that requests a URL over HTTP(S), converts the response to markdown and returns it.
This technique works for sites that serve content as full HTML, so sites that rely on scripting to serve content, such as a PWA without SSR, will not work. Check out the visual example later that uses a fully-featured browser.
const TurndownService =require("turndown") astypeofimport("turndown");asyncfunctionloadPage(url:string):Promise<string> {if (!(awaitcanCrawlUrl(url))) {console.error(`Cannot crawl ${url} due to robots.txt restrictions.`);return""; }const page =awaitfetch(url);if (!page.ok) {console.error(`Failed to fetch ${url}: ${page.statusText}`);return""; }const html =await page.text();const turndownService =newTurndownService();const markdown = turndownService.turndown(html);return markdown;}
import { FunctionDeclaration } from"@google/genai";const loadPagePageDef: FunctionDeclaration = { name:"loadPage", description:"Load a web page and return its content in Markdown format.", parameters: { type: google.Type.OBJECT, properties: { url: { type: google.Type.STRING, description:"The URL of the web page to load.", }, }, required: ["url"], }, response: { type: google.Type.OBJECT, properties: { result: { type: google.Type.STRING, description:"The requested webpage content in markdown format.", }, }, required: ["result"], },};
awaitrun("What is today's featured article on the English Wikipedia?", google.Modality.TEXT, [{ functionDeclarations: [loadPagePageDef] }],` Your job is to answer the users query using the tools available. First determine the address that will have the information and tell the user. Then immediately invoke the tool. Then answer the user. `);
Connection opened
I can load the main page of the English Wikipedia and find the featured article. The URL for that page is “https://en.wikipedia.org/wiki/Main_Page”.
In the previous example, you used a tool to retrieve a page’s textual content and use it in a live chat context. However, web pages are a rich multi-modal medium, so using text results in some loss of signal. Using a fully-featured web browser also enables websites that use JavaScript to render content, something that is not possible using a simple HTTP request like the earlier example.
In this example, you will define a tool that takes a screenshot of a web page and passes the image back to the model.
Define a graphical browser
Here you define a browseUrl function that uses Puppeteer to load a headless web browser, navigate to a URL and take a screenshot. This technique takes a single screenshot at a fixed size.
Add the browseUrl tool to a model and start a chat session. As LLMs do not directly have internet connectivity, modern models like Gemini are trained to tell users that they can’t access the internet, rather than hallucinating results. To override this behaviour, this step adds a system instruction that guides the model to use the tool for internet access.
import { FunctionDeclaration } from"@google/genai";const browseUrlPageDef: FunctionDeclaration = { name:"browseUrl", description:"Browse a web page and take a screenshot.", parameters: { type: google.Type.OBJECT, properties: { url: { type: google.Type.STRING, description:"The URL of the web page to browse.", }, }, required: ["url"], }, response: { type: google.Type.OBJECT, properties: { result: { type: google.Type.STRING, description:"The status of the operation, e.g., 'ok' or an error message.", }, }, required: ["result"], },};
const SYSTEM_INSTRUCTION =`You are a system with access to websites via the \`browseUrl\` tool.Use the \`browseUrl\` tool to browse a URL and generate a screenshot that will bereturned for you to see and inspect, like using a web browser.When a user requests information, first use your knowledge to determine a specificpage URL, tell the user the URL and then invoke the \`browseUrlPageDef\` with this URL. Thetool will supply the website, at which point you will examine the contents of thescreenshot to answer the user's questions. Do not ask the user to proceed, just act.You will not be able to inspect the page HTML, so determine the most specific pageURL, rather than starting navigation from a site's homepage.`;const chat = ai.chats.create({ model: MODEL_ID, config: { tools: [{ functionDeclarations: [browseUrlPageDef] }], systemInstruction: SYSTEM_INSTRUCTION, },});const r =await chat.sendMessage({ message:"What is trending on YouTube right now?",});showParts(r);
I will browse the YouTube trending page at https://www.youtube.com/feed/trending.
You should see a functionCall in the response above. Once the model issues a function call, execute the tool and save both the functionResponse and the image for the next turn.
If you do not see a functionCall, you can either re-run the cell, or continue the chat to answer any questions the model has (e.g. r = await chat.sendMessage({ message: "Yes, please use the tool" }));
import { Part } from"@google/genai";let functionResponse: Part;const parts = r.candidates?.[0]?.content?.parts?? [];for (const part of parts) {if (part.functionCall) {console.assert(part.functionCall.name==="browseUrl","Expected function call to be browseUrl");const url = part.functionCall.args?.urlasstring;console.log(`Browsing URL: ${url}`);const response =awaitbrowseUrl(url);console.log(`Response: ${response}`);if (response !=="ok") {console.error(`Failed to browse URL ${url}: ${response}`); } functionResponse = google.createPartFromFunctionResponse(part.functionCall.id, part.functionCall.name, { result: response, }); }}
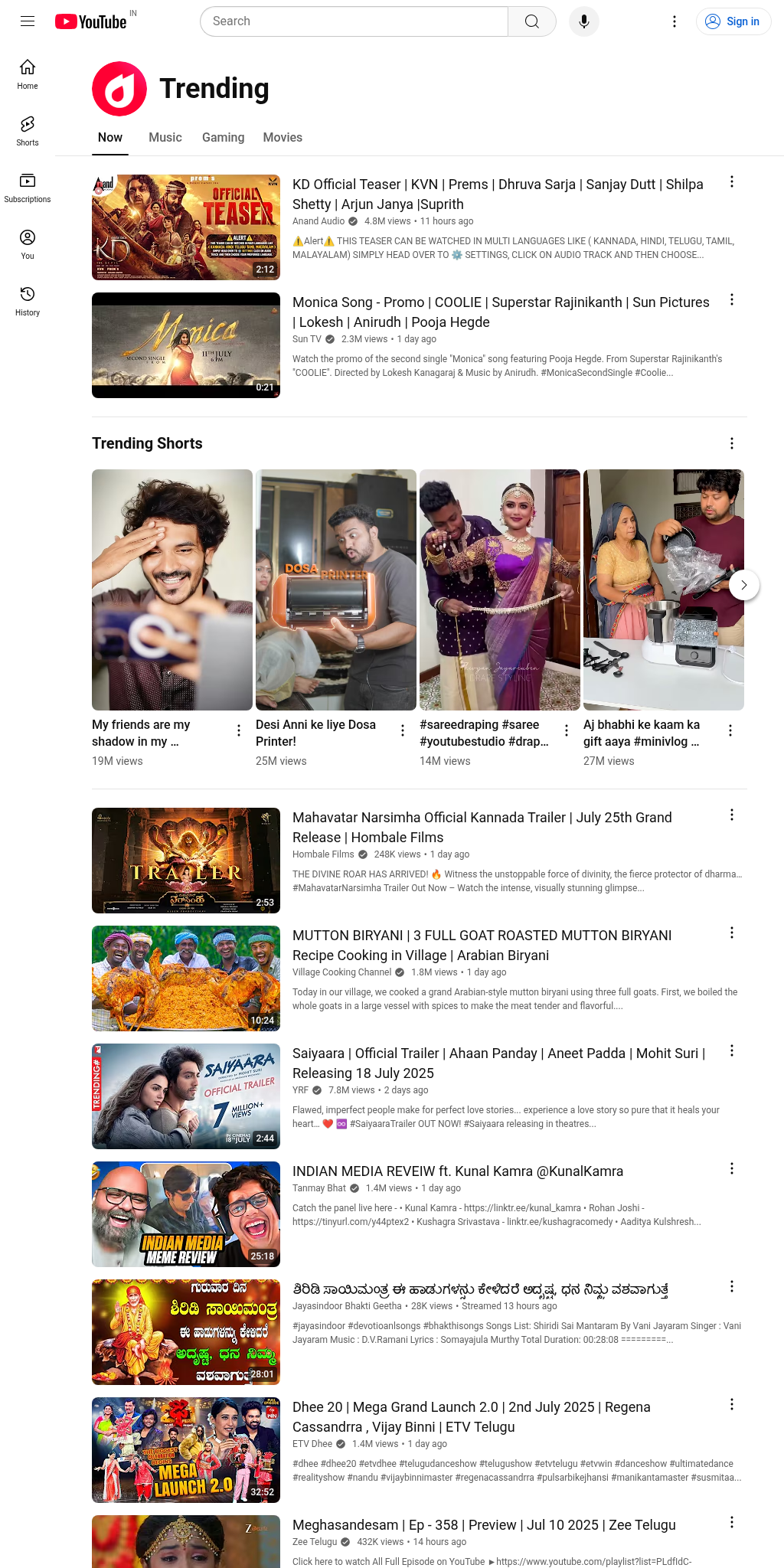
Browsing URL: https://www.youtube.com/feed/trending
Screenshot saved to ../assets/browser_as_a_tool/screenshot.png
Response: ok
Inspect the image before it is sent back to the model. Depending on where you are running this, you may see localised content. If you are using Google Colab, you can run !curl ipinfo.io to see the geolocation of the running kernal.
Note that if you see a semi-blank image, the page may not have fully loaded. Try adjusting the sleep duration in browseUrl, or provide a suitable implementation for the pages you are using in your application.
“Aj bhabhi ke kaam ka gift aaya #minivlog …” (27M views)
Browse local services
By providing a browse tool that you run in your own environment, you can connect it to your own private services - such as your home network or intranet.
This example demonstrates how to connect the browse tool to a simulated intranet environment.
Screenshot saved to ../assets/browser_as_a_tool/screenshot.png
Finally, start a chat that uses the loadPage tool. Include instructions on how to access and navigate the intranet.
Note
If the data you provide to the model is at all sensitive, be sure to read and understand the terms and conditions for the Gemini API, specifically the terms governing how data is processed for paid vs unpaid services.
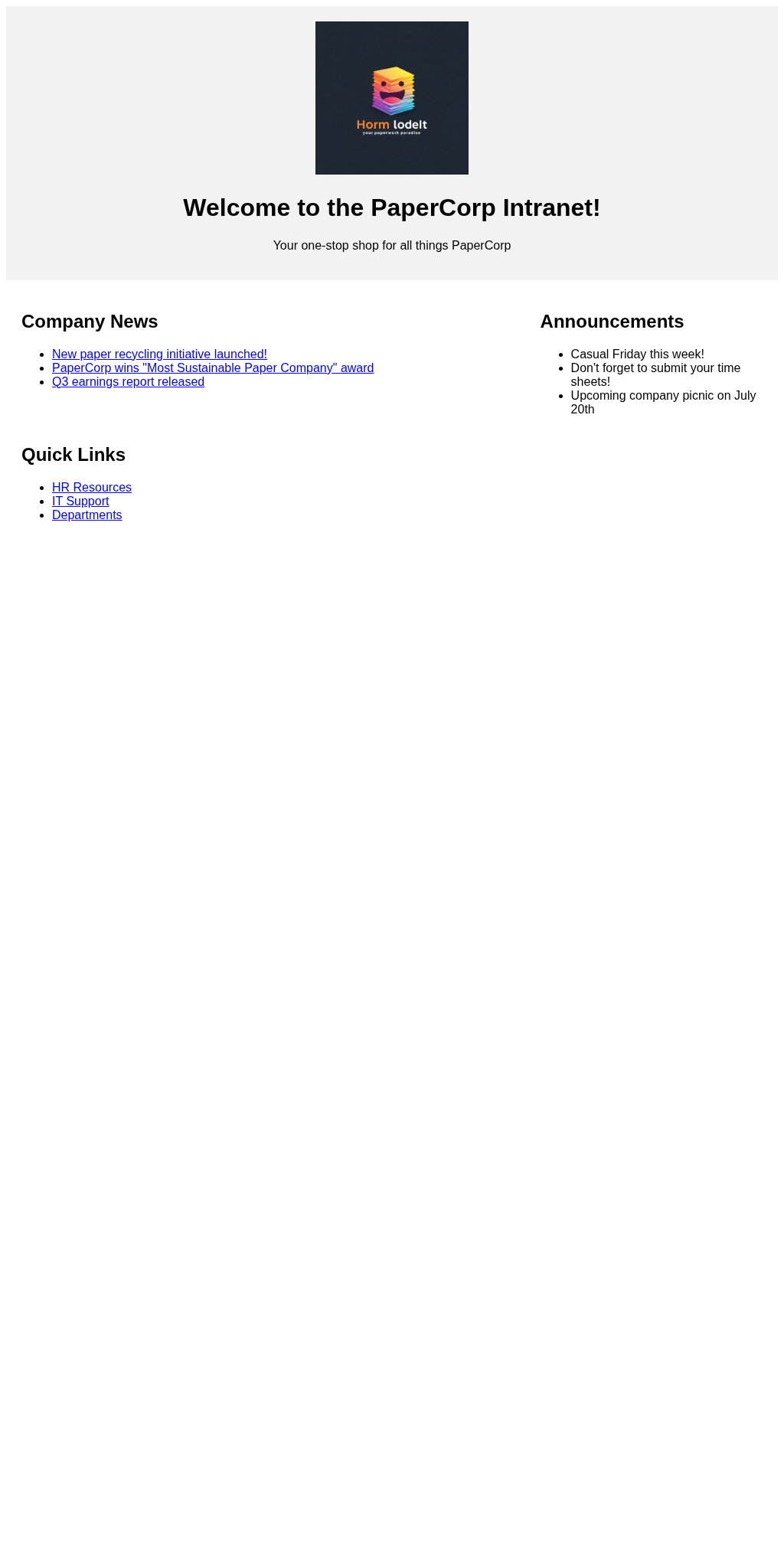
const PAPER_CORP_SYSTEM_INSTRUCTION =` Use the tools you have to answer the user's questions about the "PaperCorp" company. You have access to web pages through the \`loadPage\` tool, including access to the local network and intranet, where you will find information about the company. The \`loadPage\` tool will return you the page contents as Markdown. The intranet hostname is \`papercorp\`, and the home page can be accessed via http://localhost:8080. Unless you know an address already, start navigating from the home page to find other pages.`;const paper_corp_chat = ai.chats.create({ model: MODEL_ID, config: { tools: [loadPageTool], systemInstruction: PAPER_CORP_SYSTEM_INSTRUCTION, },});const stream =await paper_corp_chat.sendMessageStream({ message:"What forms are available through HR?",});forawait (const chunk of stream) {showParts(chunk);}
{
"thoughtSignature": "CiwBVKhc7k+mAhFaUMhzli8xM7D6GNQx4ApsJvXq6Yj5oZIT94XhCeXnxgNXIwqEAQFUqFzucj+yJ8JZ7jAwZeEzyfkYn0+Fr7sWegQovyExMYKa7Otj15iy0AItBb8AmDlTYlWUhd4fXQpLsoOw+nHbtPd2Rj9UcnqVThXN6Y5Vme4gr2H97Sgl4SrGOdz+dbSjs/ok/WRNXCWrVtxyokeb09m9mUB6C+M/3HNvF+B8BMVfCgqfAQFUqFzu7sgaDSv+GMBwnyQdU0Zj8ovM1neJoJ0lpJsXaP2U6LMkdaPUun6XrqDPCjKCpGbg7t92ZPTTTpfF4EbQ7jcNdkJu1GTyVD0/bylfNEfCCBObpdh3f5/tLEK1PJ8GLpdvc+NwrEaTPM3Yl8mfzrmf6dIi9O7+H3Kdwl3ptVSS14npcbLHRsz2Hwrhm0/dAtXZpmyGrRiQ3PCEjA==",
"functionCall": {
"name": "loadPage",
"args": {
"url": "http://localhost:8080"
}
}
}
{
"functionResponse": {
"id": "",
"name": "loadPage",
"response": {
"result": "Welcome to PaperCorp Intranet body { font-family: sans-serif; } .header { background-color: #f2f2f2; padding: 20px; text-align: center; } .logo { max-width: 200px; } .content { padding: 20px; } .news { float: left; width: 60%; } .announcements { float: right; width: 30%; } .clearfix::after { content: \"\"; clear: both; display: table; }\n\n\n\nWelcome to the PaperCorp Intranet!\n==================================\n\nYour one-stop shop for all things PaperCorp\n\nCompany News\n------------\n\n* [New paper recycling initiative launched!](news.html)\n* [PaperCorp wins \"Most Sustainable Paper Company\" award](news.html)\n* [Q3 earnings report released](news.html)\n\nAnnouncements\n-------------\n\n* Casual Friday this week!\n* Don't forget to submit your time sheets!\n* Upcoming company picnic on July 20th\n\nQuick Links\n-----------\n\n* [HR Resources](hr.html)\n* [IT Support](it.html)\n* [Departments](departments.html)"
}
}
}
{
"thoughtSignature": "Ci4BVKhc7utxf7EVtE8IW9CAQzLL2Cfwl19egxfpqOBMv4J9nU83EzIv/88ay/Z7CmsBVKhc7nfAhGszzuM9I8mZGQMY6CMlDjFLcr/nXbrg034IwlzaAsHmAUY9vGpcjigETLRKGD22JXRzoF5O9DC6gkdWhNZbN+rMJ31TOc5x60ZuTJw/S8tfyjt2J2OBmFPMqBcuSaS1NTezfwpyAVSoXO4CZL8fv17YPHJ5EaZrcW7hoX1f2LraRQ8QymYnfRl8YsKn3fy26b39DR9sQTMJjwoAZXL1zeUSUJxAR7mol7Twn0JAWG2kfAk9cXcXqKRkQ6WhEyY09jgJeFNyMxc1t6nHn8/+U6s4L68Q0K2P",
"functionCall": {
"name": "loadPage",
"args": {
"url": "http://localhost:8080/hr.html"
}
}
}
{
"functionResponse": {
"id": "",
"name": "loadPage",
"response": {
"result": "PaperCorp - HR Resources body { font-family: sans-serif; } .header { background-color: #f2f2f2; padding: 20px; text-align: center; } .logo { max-width: 200px; } .content { padding: 20px; } .resource-list { list-style: disc; padding-left: 40px; }\n\n\n\nHR Resources\n============\n\nPolicies & Procedures\n---------------------\n\n* [Employee Handbook](#)\n* [Code of Conduct](#)\n* [Vacation Policy](#)\n* [Sick Leave Policy](#)\n* [Performance Review Process](#)\n\nForms & Documents\n-----------------\n\n* [Expense Report Form](#)\n* [Time Off Request Form](#)\n* [Benefits Enrollment Form](#)\n* [Tax Forms (W-2, etc.)](#)\n\nContact HR\n----------\n\nIf you have any questions or concerns, please don't hesitate to contact the HR department:\n\nEmail: [hr@papercorp.com](mailto:hr@papercorp.com)\n\nPhone: (555) 555-5555"
}
}
}